
Why are enterprise systems so terrible?
Large enterprise IT systems have a bad reputation for being overly complex, costly to maintain, and opaque/inflexible. In my 15-year career in financial services, I have yet to come across anyone who is happy with their company’s IT infrastructure. And this problem is certainly not unique to banking, but is present across all industries. Why is that?
First, we need to understand what an enterprise system is. Not all software used in an organization qualifies as an enterprise system. Excel, for example, wouldn’t be considered an enterprise system in itself. A true enterprise system usually shares (most of) the following characteristics:
Distributed, designed to handle large volumes of data and/or computations
Mission critical, with low tolerance for service disruptions
Solves enterprise wide problems, services multiple teams and departments
Changes are constantly needed in response to evolving business requirements
If regulated, must adhere to strict industry and government standards
A bank’s trading and risk management system is a good example of an enterprise system, and it features all the attributes above. These characteristics dictate that a good enterprise system should be scalable, reliable, transparent, and easily modifiable.
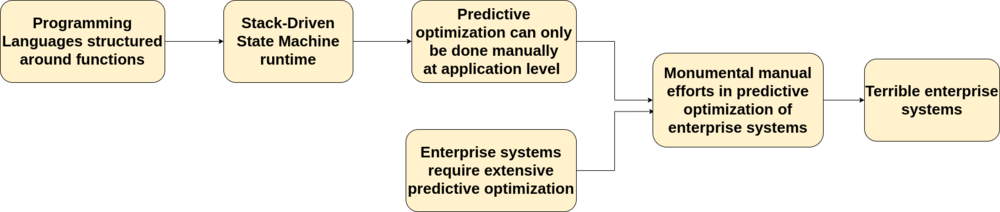
Let me point out an important fact that is often taken for granted: the runtime of any general purpose programming language today is essentially a stack-driven state machine (SDSM). What do I mean by that? The source code of every modern programming language is structured as a collection of functions. The call sequence of these functions at run time is determined by call stacks, usually one for each running thread. Call stacks store the essential information for determining the correct call sequence of all the functions at run time. When a function is called, its calling parameters, local variables, and return values are pushed to or allocated at the top of the stack; when the function exits, its states are popped off the top of the stack, the program returns control to the enclosing function whose state becomes the new stack top. The shared state of the program is kept in the heap, which can be accessed and modified from any function as long as it holds a reference (i.e., a pointer) to the right address in the heap.
The stack driven state machine (SDSM) is behind the execution of almost every general purpose programming language because the stack is the most efficient data structure for managing the call sequence of functions. However, the SDSM runtime also has some notable limitations:
The call stacks and heap are created and updated dynamically at run time, their state is highly path-dependent and unpredictable. Different execution paths may take place at run time depending on the input data. The SDSM itself does not maintain any data structure to help predict a program's future runtime behavior.
The SDSM runtime does not keep track of data dependency or lineage, neither are intermediate results persisted. Once data is popped from the stack, or de-allocated from the heap, it is no longer accessible. Any caching, lineage, or reporting of intermediate results can only be implemented as part of the application logic.
The stacks and heap of SDSM must live in the same memory address space, which means that SDSM only has information about a single running process, thus offering no support for any multi-process execution and communication. As a result, any inter-process communication and coordination can only be implemented at the application level.
A direct consequence of these limitations is that SDSM cannot support predictive optimizations. By predictive optimization, I mean those that only pay off under certain specific runtime outcomes, but not for all. Therefore, some knowledge or prediction on future runtime behaviors are required in order to determine whether these optimizations should be applied. The following are some examples of predicative optimizations:
The result of a function call is cached for certain input parameters, knowing that the same function will be called again with the same inputs.
An input data is changed, only those affected parts are updated instead of rerunning the entire calculation, knowing the full dependency on that input.
Memory is pre-allocated for better memory performance, knowing the future memory consumption of the program.
None of these optimizations are possible within the SDSM runtime, as it does not track any data to predict future run time behaviors. As a result, predictive optimizations can only be implemented manually at the application level by developers.
When writing single process applications, developers can often reason about and predict their runtime behaviors to some limited extent based on experience, then implement corresponding predictive optimizations, such as caching or memory optimizations. However, as an application grows in its complexity, its overall run time behavior often becomes too difficult to predict from experience. Instead developers have to rely upon tools such as profilers or benchmarks to gather runtime data on the overall applications for better predictions and optimizations.
Predictive optimization is critical for the success of any enterprise system. Compared to single process applications, the stakes are much higher in an enterprise system because there are many more design and implementation choices to make. This includes the system topology, communication protocols, caching, distribution, load-balancing and redundancy strategy etc. Each of these choices could lead to very different trade-offs in a system’s cost, reliability, performance, and scalability. It is therefore extremely important to carefully optimize the enterprise system for its expected runtime needs. A bad design or implementation choice could easily make an enterprise system unfit for its purpose, and would be extremely expensive to fix after the system is built.
Implementing predictive optimization for an enterprise system is orders of magnitude more difficult than a single process application, because:
The runtime behavior of an enterprise application is much more difficult to predict, as it often involves many processes running on many computers. The benchmarking and profiling tools are unreliable as there are too many uncontrollable variables that can affect its runtime behavior, such as synchronization, network latency, work load, database response time, 3rd party services etc.
The changing business needs have to be considered. An enterprise system not only has to be optimized for a company’s current needs, but also for its expected future needs. We all know how difficult it is to predict the future.
A firm usually runs multiple distributed applications, which are developed and supported by different teams, departments or vendors, often with different priorities and objectives. These distributed applications are frequently built using shared components and services across the firm, such as databases, workflows, computation engines etc.
Consequently, the predictive optimization for enterprise systems is an extremely complex high dimensional optimization of many interdependent components, services and applications, with multiple objectives and constraints, and ambiguous future business needs. The objectives and constraints can be either technical or business related, and the latter may include resourcing, budget, project timelines, etc.
Such a complex predictive optimization problem itself is challenging enough; what makes it truly terrible is that it has to be done manually at the application level without reliable runtime information due to the limitations imposed by SDSM runtime. In practice, the manual predictive optimization for distributed applications can manifest as various work streams and activities among teams of people in an organization. This would include architecture/system design, implementation, project planning, performance monitoring and tuning, support and maintenance, etc. These seemingly unrelated work streams are often just different aspects of the manual predictive optimization of a typical enterprise system.
Despite the monumental cost and effort involved, manual predictive optimization rarely results in an optimal enterprise system. Oftentimes it doesn’t even produce a reliable one, mainly due to the inability to accurately predict the runtime behavior and future needs of a business. After the system is built, making material changes is incredibly difficult and time-consuming, as the manual predictive optimization has to be iterated to take account of the changes. This is why most enterprise systems today are overly complex, expensive, opaque, difficult to modify, and poor in performance, scalability and reliability.
By now, it might surprise you that the unavoidable logical conclusion is that today’s programming languages are responsible, at least in part, for the current state of enterprise systems. Let’s recap the entire chain of logic in a single diagram:
A number of technologies have emerged aiming to ease the pain of building and maintaining enterprise systems. The industry has gradually converged to a consensus of “best practices” around building distributed systems using small and loosely coupled components and services. The recent popularity in microservices architecture is an example of that “best practice”. Even though they may help ease some of the symptoms listed above, these “best practices” do not address the root cause. A monumental amount of manual predictive optimization work is still required for complex enterprise systems even after following these “best practices”.
Once we understand that the root cause of terrible enterprise systems lives in the SDSM runtime and programming languages, we can start formulating a real solution. This calls for a new breed of design language that is not structured around functions and a new kind of runtime that supports accurate predictions of future behaviors. It would also have the ability to automate most of the predictive optimization for single process or distributed applications. Only with that kind of runtime, can an enterprise system be truly self-adaptive to changing business needs.
You may think this sounds too good to be true, akin to a fairy tale in the technology landscape. Actually that solution is in fact feasible, and we will be writing about it in future articles, so stay tuned…